Node.js
The Scorecard platform helps you evaluate the performance of your LLM app to ship faster with more confidence. In this quickstart we will:
- Get an API key and create a Testset
- Create an example LLM app
- Execute a script with the Scorecard SDK within our production application
- Review results in the Scorecard UI
Setup
First let’s create a Scorecard account and find your Scorecard API Key. Then we’ll get a OpenAI API Key, and set these as environment variables and also install the Scorecard and OpenAI Node Libraries:
Create Testcases
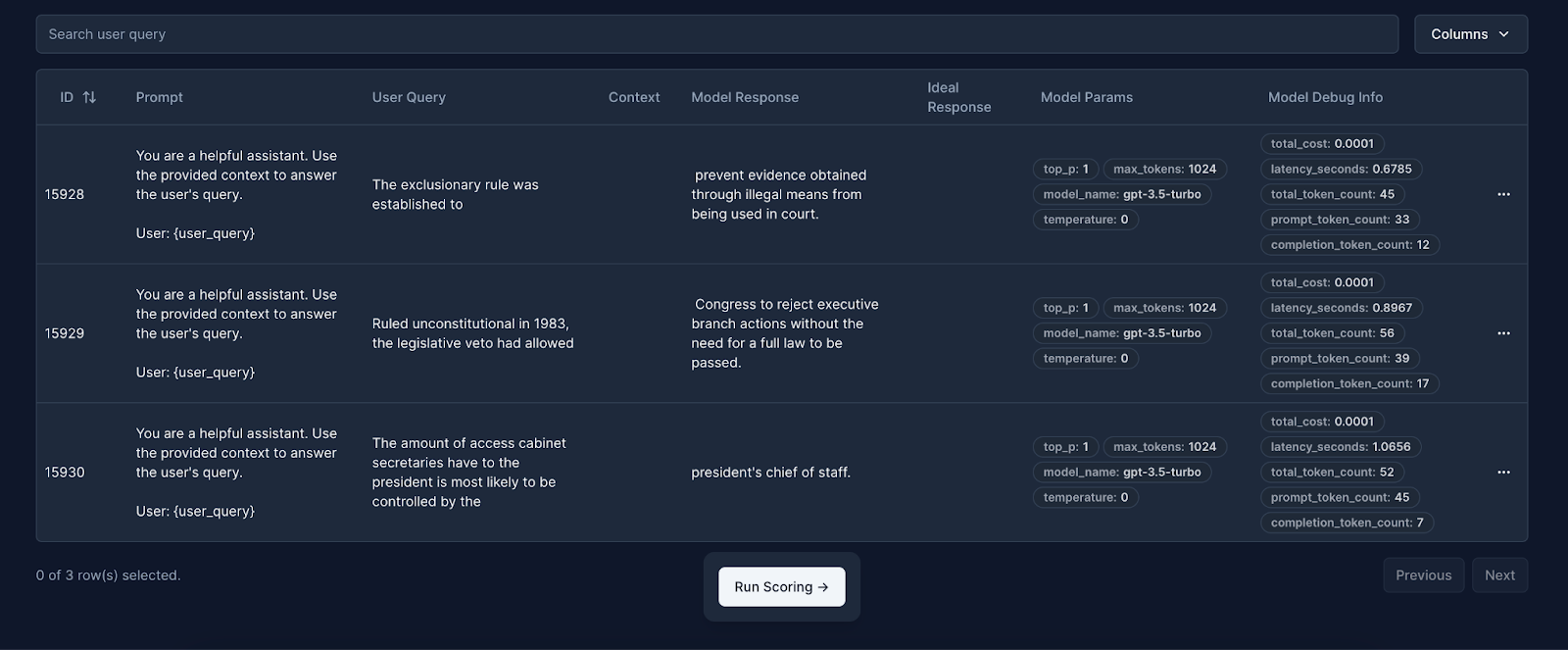
Now let’s create and run a create_testset.js script to create a testset and add some test cases using the SDK. Test cases are a way to collect examples that you can run evaluations against and improve over time. After we create a testset we’ll grab that testset ID to use later:
Create Test System
Next let’s create a function which will represent our system under test. Here we’ve created a system that will be a helpful assistant in response to our input user query.
Create Metrics
Now that we have a system that answers questions from the MMLU dataset, let’s build a metric to understand how relevent the system responses are to our user query. Let’s go to the Scoring Lab and select “New Metric”
 Scoring Lab: New Metric
Scoring Lab: New MetricFrom here let’s create a metric for answer relevency:
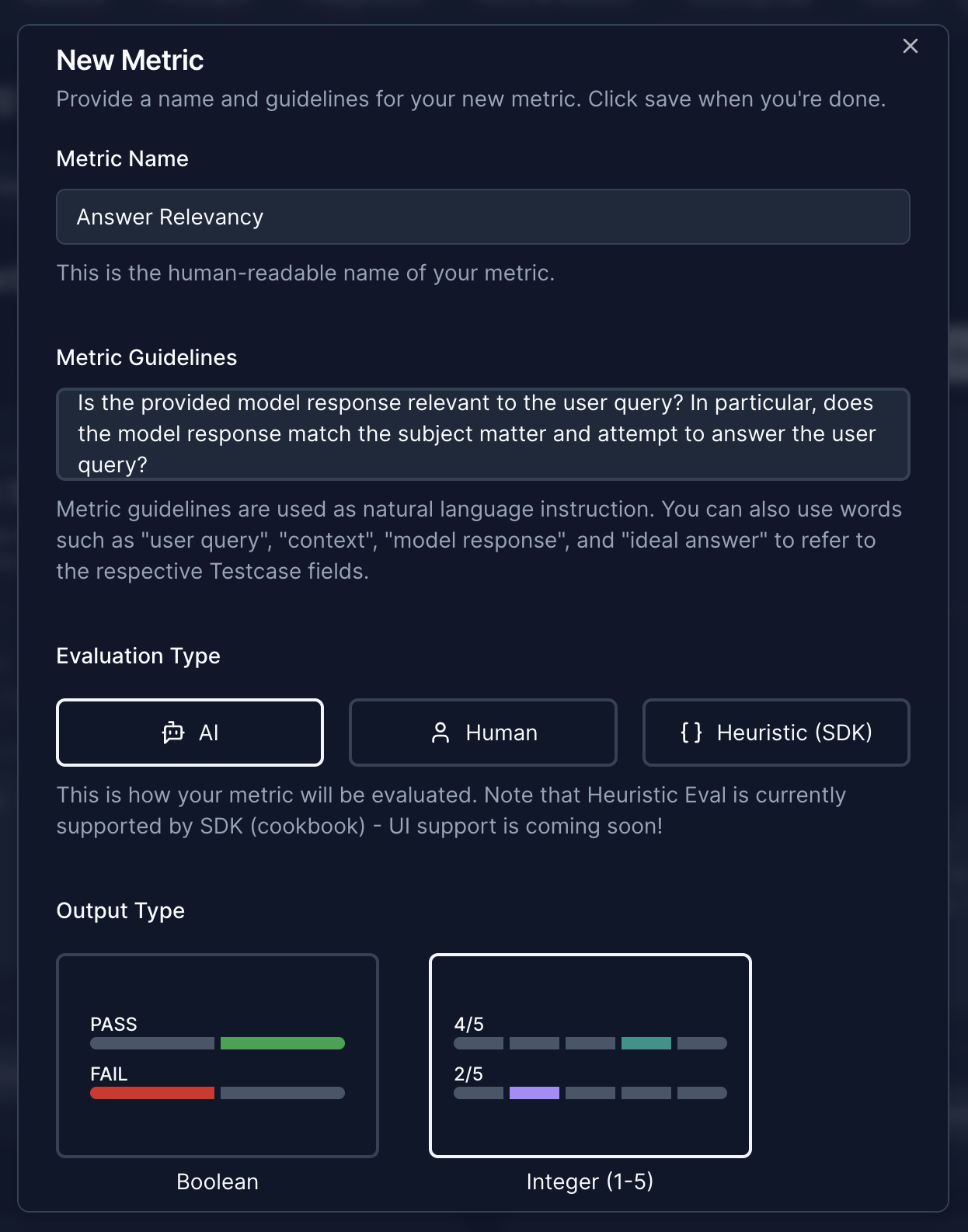 Defining the Metric Answer Relevancy
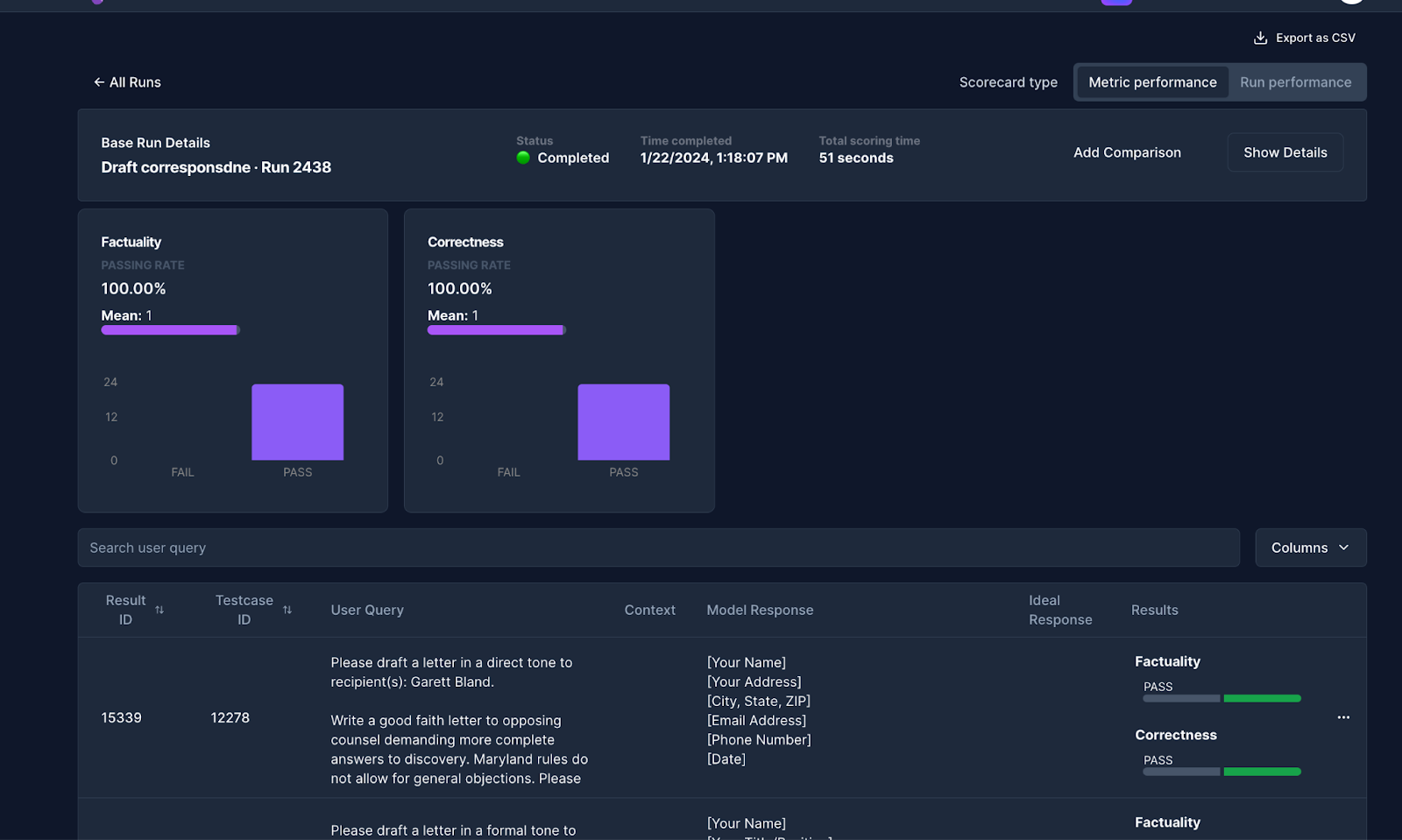
Defining the Metric Answer RelevancyYou can evaluate your LLM systems with one or multiple metrics. A good practice is to routinely test the LLM system with the same metrics for a specific use case. For this, Scorecard offers to define Scoring Configs, collection of metrics to be used to consistently evaluate LLM use cases with the same metrics. For the quick start, we will create a Scoring Config just including the previously created Answer Relevancy metric. Let’s head over to the “Scoring Config” tab in the Scoring Lab and create this Scoring Config. Let’s grab that Scoring Config ID for later:
 Create a Scoring Config Including the Answer Relevancy Metric
Create a Scoring Config Including the Answer Relevancy MetricCreate Test System
Now let’s use our mock system and run our Testset against it replacing the Testset id below with the Testset from before and the Scoring Config ID above: